Text Mining
USING TIDY DATA PRINCIPLES
Acknowledgements

What do we mean by tidy text?

text <- c("Tell all the truth but tell it slant —",
"Success in Circuit lies",
"Too bright for our infirm Delight",
"The Truth's superb surprise",
"As Lightning to the Children eased",
"With explanation kind",
"The Truth must dazzle gradually",
"Or every man be blind —")
text
#> [1] "Tell all the truth but tell it slant —"
#> [2] "Success in Circuit lies"
#> [3] "Too bright for our infirm Delight"
#> [4] "The Truth's superb surprise"
#> [5] "As Lightning to the Children eased"
#> [6] "With explanation kind"
#> [7] "The Truth must dazzle gradually"
#> [8] "Or every man be blind —"What do we mean by tidy text?
library(tidyverse)
text_df <- tibble(line = 1:8, text = text)
text_df
#> # A tibble: 8 × 2
#> line text
#> <int> <chr>
#> 1 1 Tell all the truth but tell it slant —
#> 2 2 Success in Circuit lies
#> 3 3 Too bright for our infirm Delight
#> 4 4 The Truth's superb surprise
#> 5 5 As Lightning to the Children eased
#> 6 6 With explanation kind
#> 7 7 The Truth must dazzle gradually
#> 8 8 Or every man be blind —What do we mean by tidy text?
Jane wants to know…
A tidy text dataset typically has
- more
- fewer
rows than the original, non-tidy text dataset.

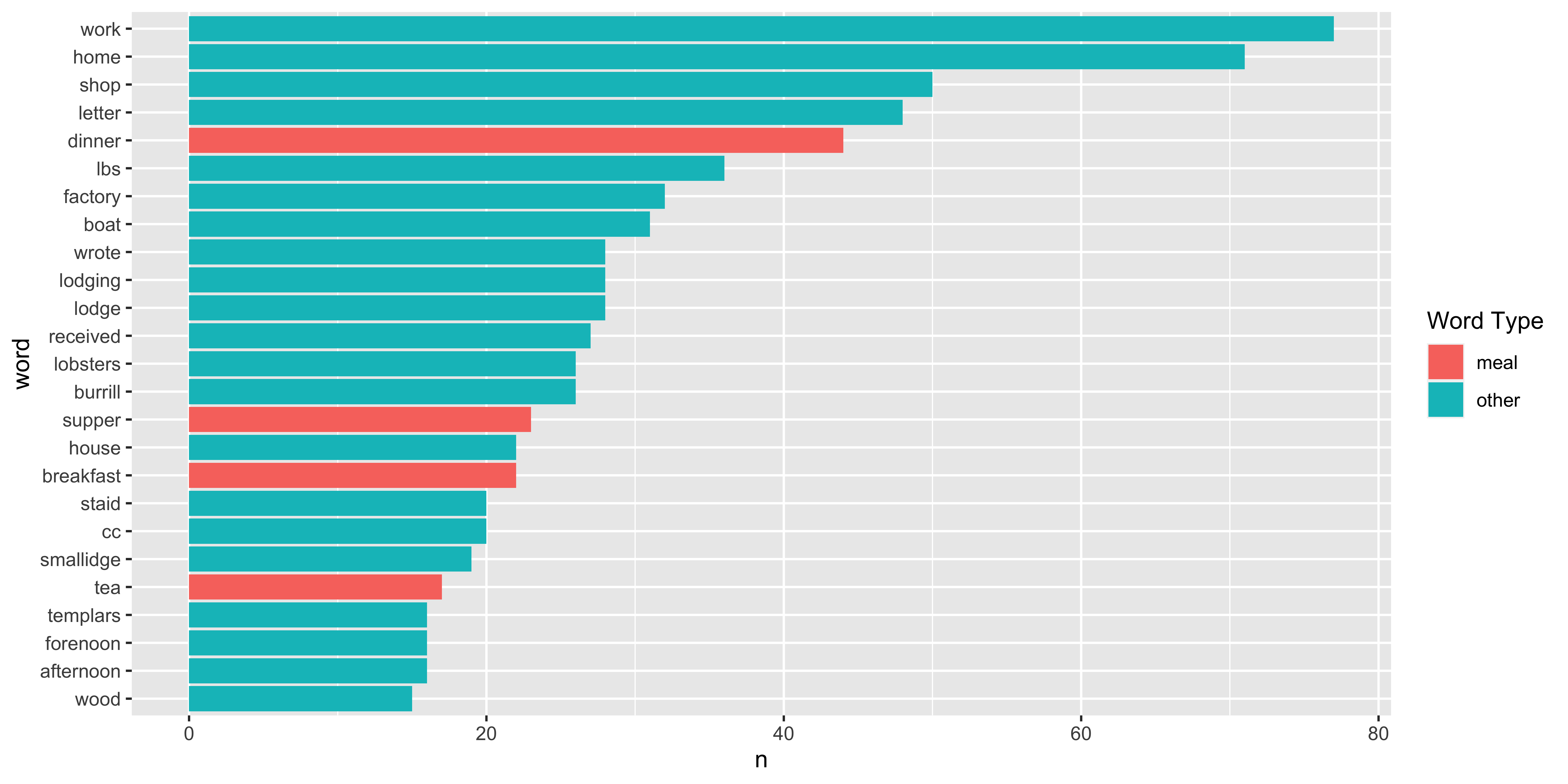
Journal 1: Boats, Meals, Goods 🍳 ⛵🦞 🪵
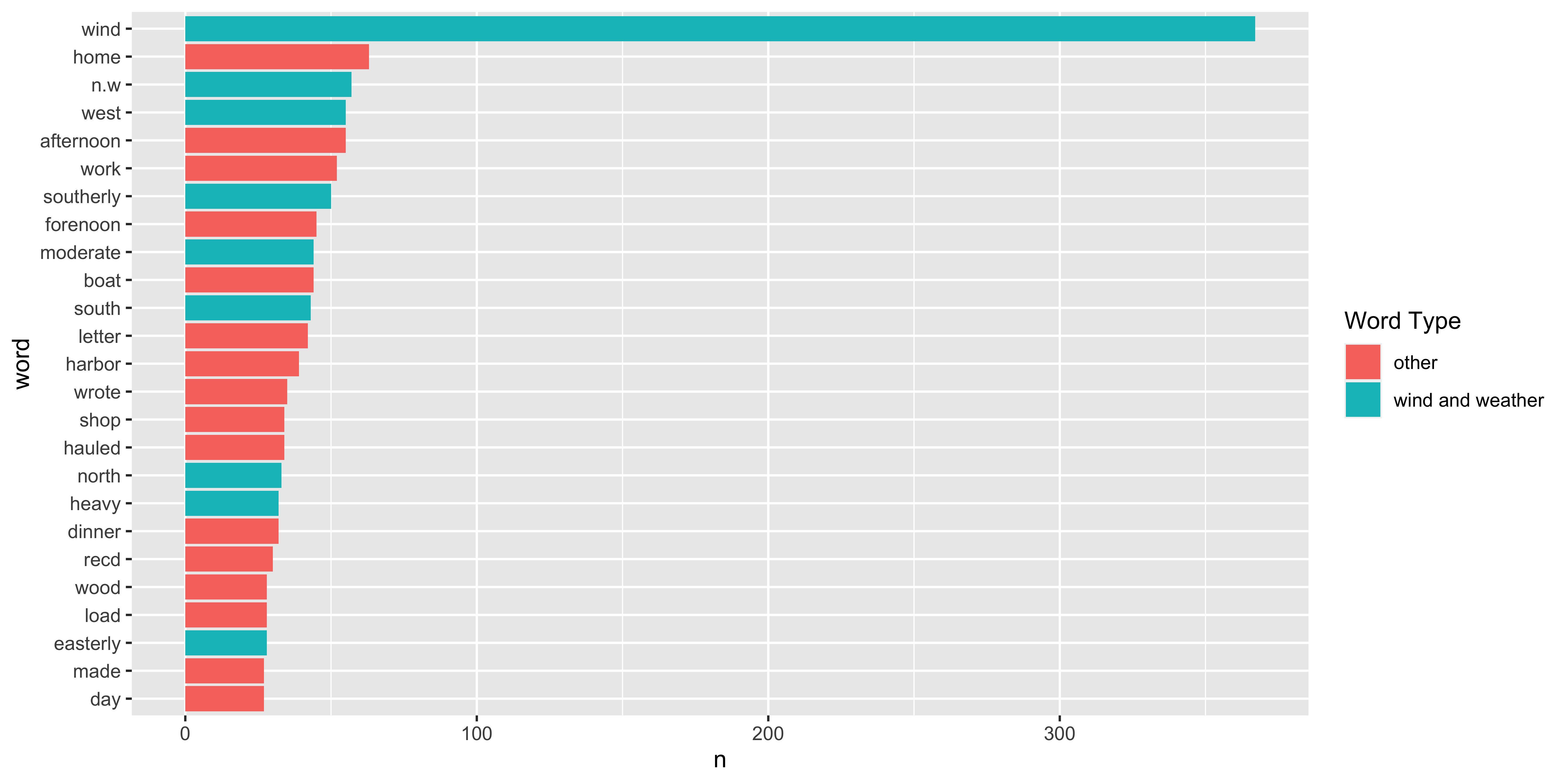
Journal 2: Wind and Weather ☁︎ NESW
Jane wants to know…
What kind of join is appropriate for sentiment analysis?
- anti_join()
- full_join()
- outer_join()
- inner_join()

Was Freeland Sentimental?

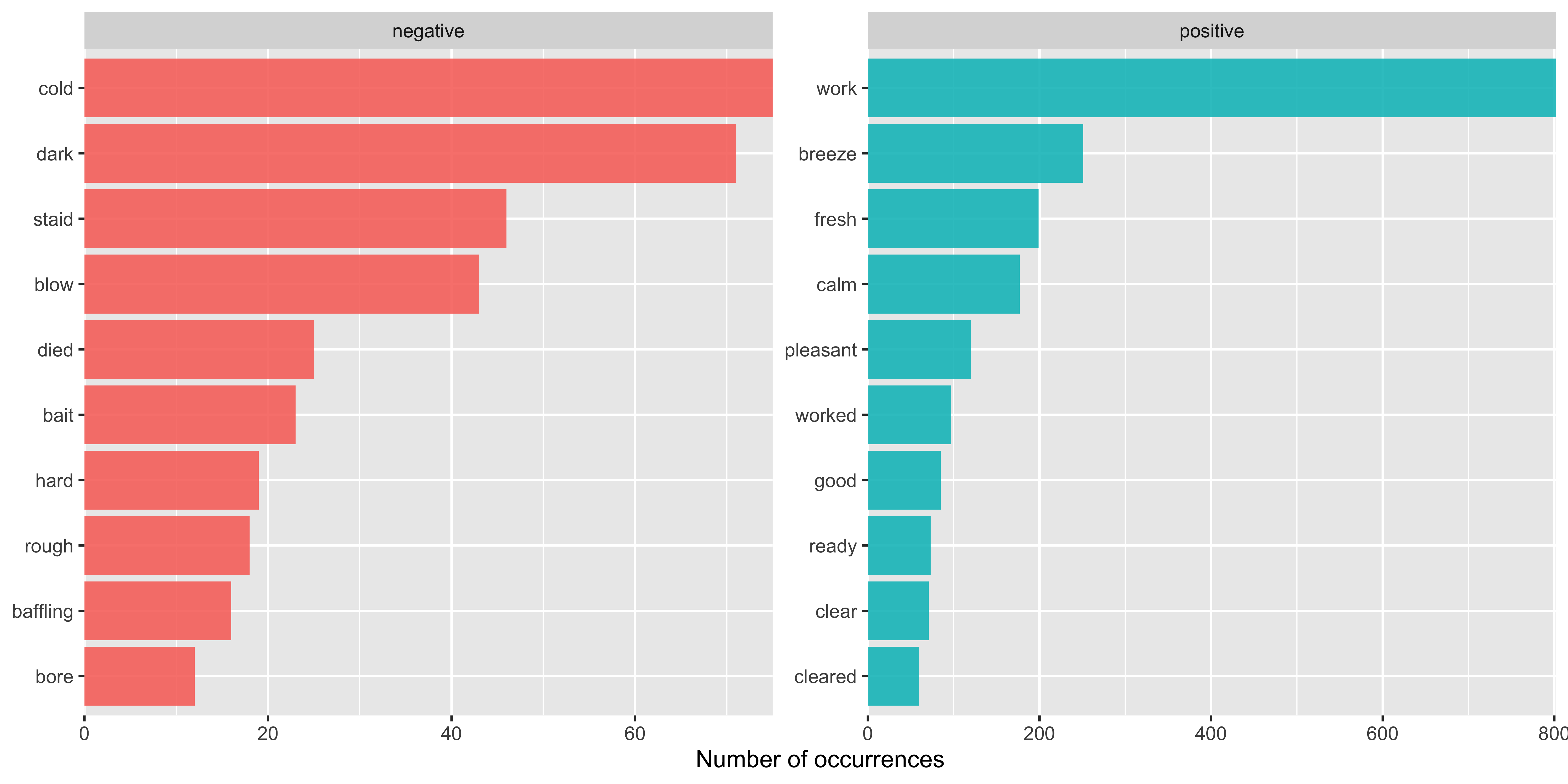
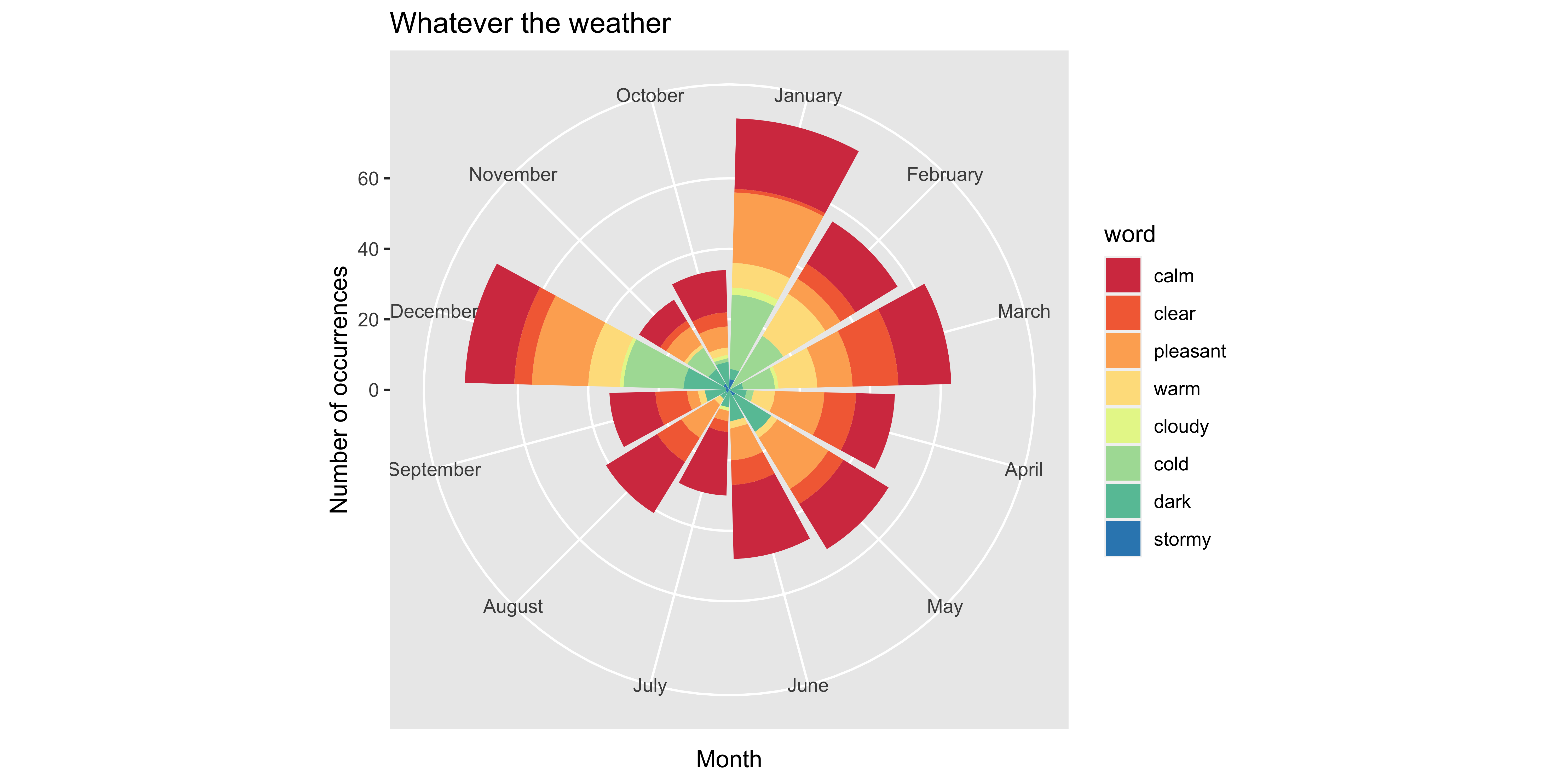
Jane wants to know…
Can we use an anti_join() now to remove stop words?
- Yes! ✅
- No ☹️
Thanks!