Mining Historical Texts
USING TIDY DATA PRINCIPLES
Acknowledgements

Slide Structure, Content, and Design adapted from Julia Silge
What do we mean by tidy text?

journal_text <- c("Was married at home in evening by William Rand Esqr.",
"Went to meeting.",
"Shooting match all day in the evening to Christmas Tree at the Hall.",
"About home at work fobbing.",
"Work about home.",
"To work in shop.",
"To work in shop.",
"Went to meeting.")
journal_text
#> [1] "Was married at home in evening by William Rand Esqr."
#> [2] "Went to meeting."
#> [3] "Shooting match all day in the evening to Christmas Tree at the Hall."
#> [4] "About home at work fobbing."
#> [5] "Work about home."
#> [6] "To work in shop."
#> [7] "To work in shop."
#> [8] "Went to meeting."What do we mean by tidy text?
library(tidyverse)
journal_df <- tibble(line = 1:8, text = journal_text)
journal_df
#> # A tibble: 8 × 2
#> line text
#> <int> <chr>
#> 1 1 Was married at home in evening by William Rand Esqr.
#> 2 2 Went to meeting.
#> 3 3 Shooting match all day in the evening to Christmas Tree at the Hall.
#> 4 4 About home at work fobbing.
#> 5 5 Work about home.
#> 6 6 To work in shop.
#> 7 7 To work in shop.
#> 8 8 Went to meeting.What do we mean by tidy text?
Freeland wants to know…
A tidy text dataset typically has
- more
- fewer
rows than the original, non-tidy text dataset.
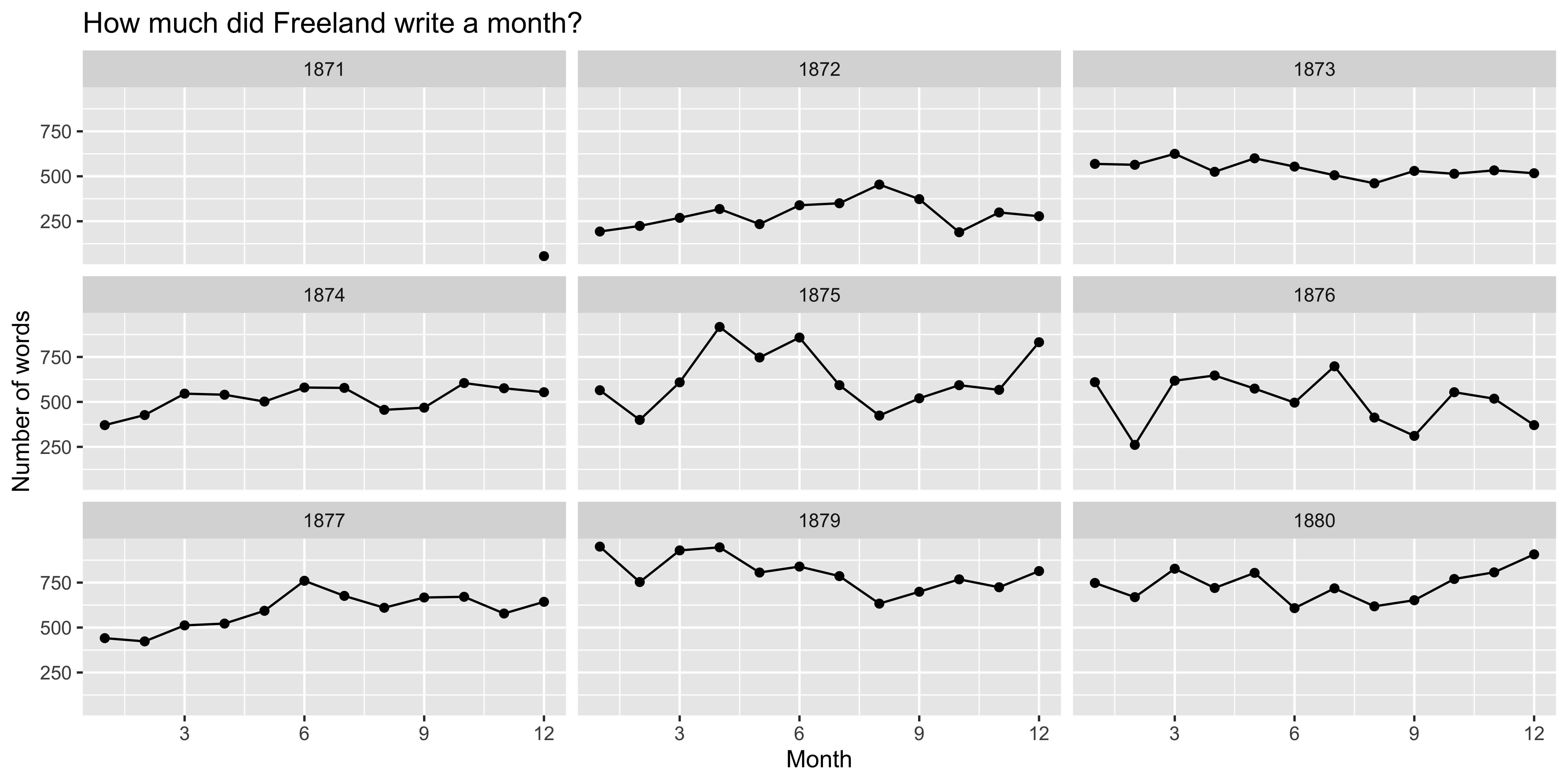
How much did Freeland write?
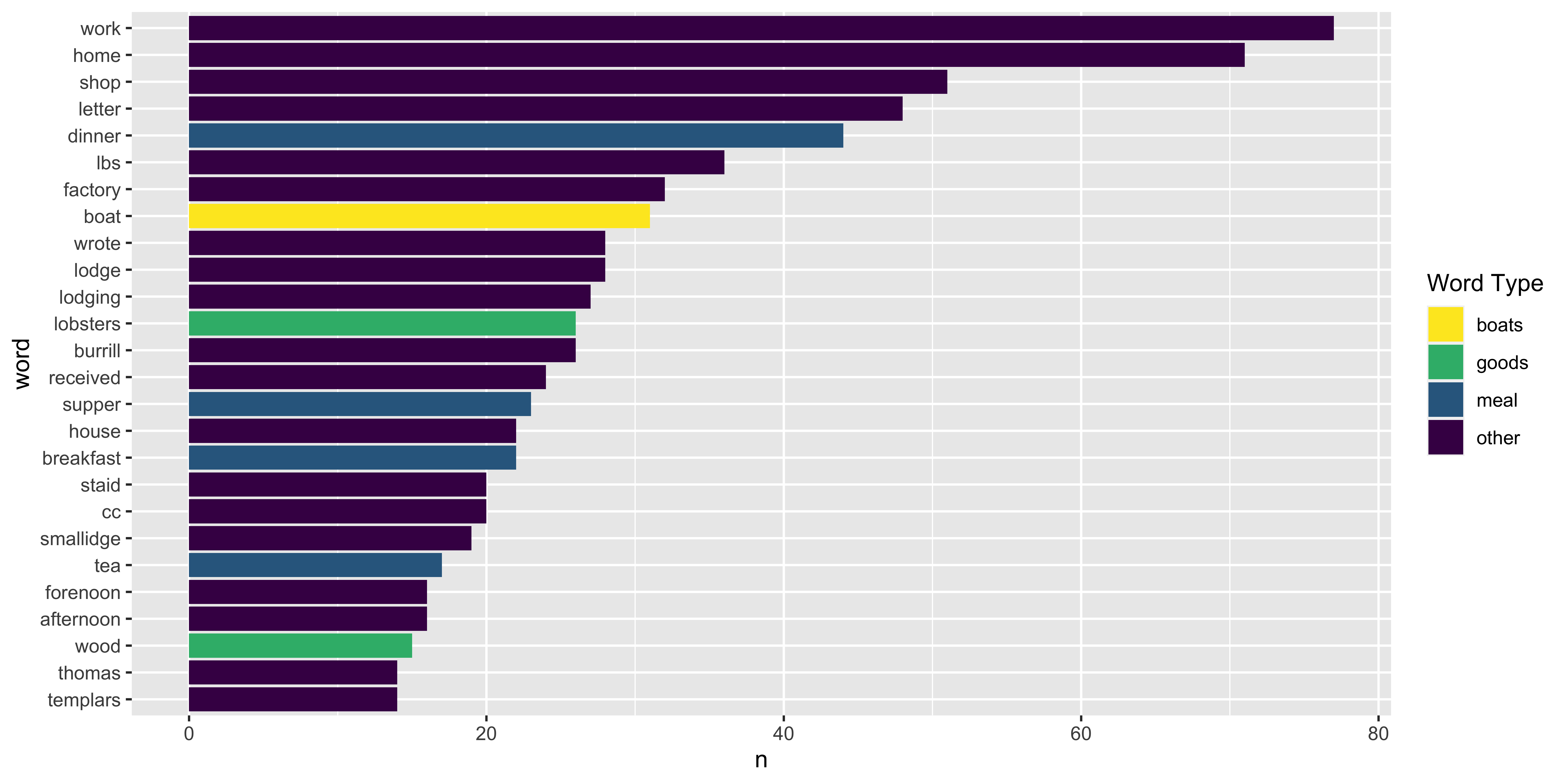
Journal 1: Boats, Meals, Goods 🍳 ⛵🦞 🪵
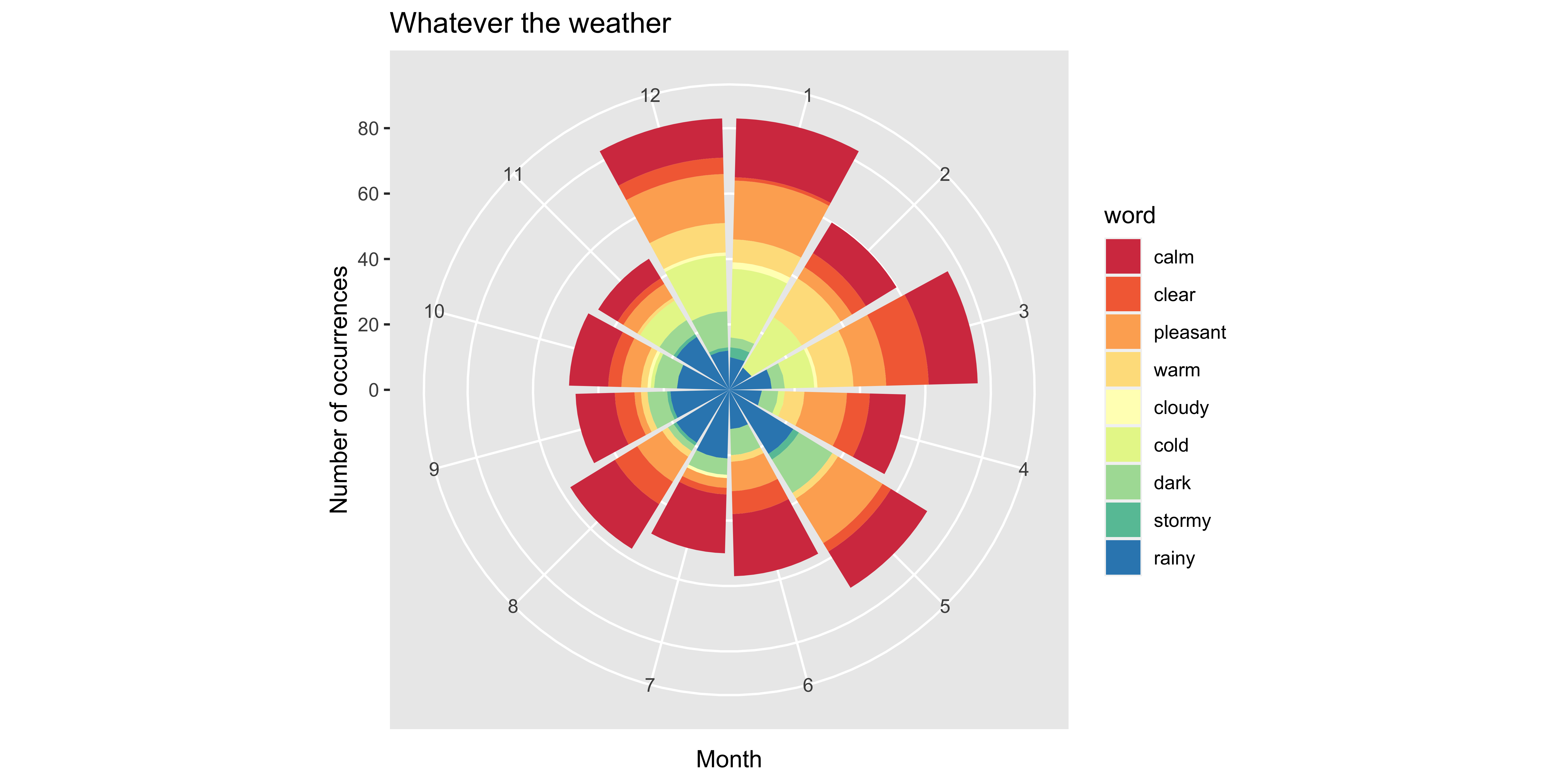
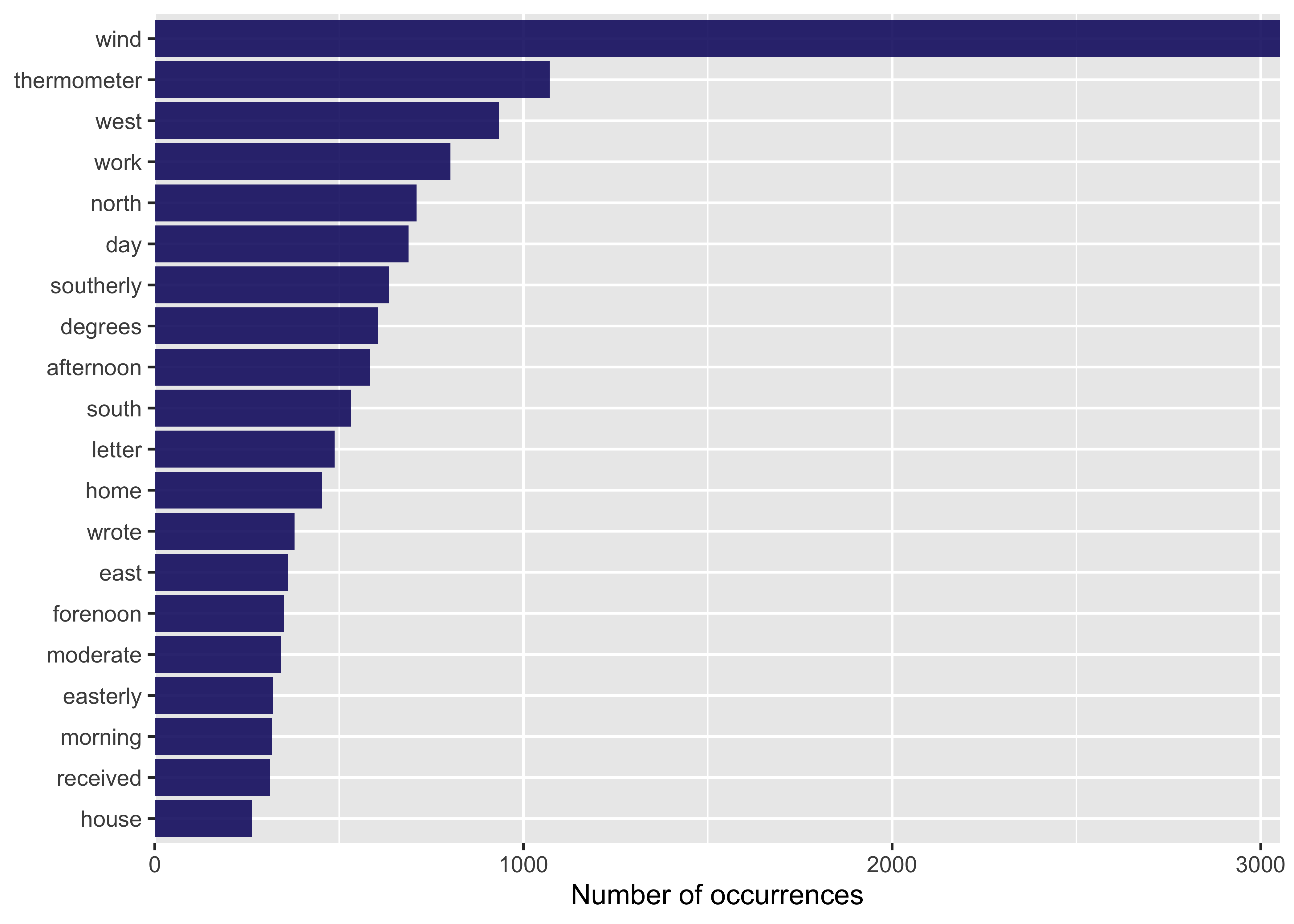
Journal 2: Wind and Weather︎ NESW
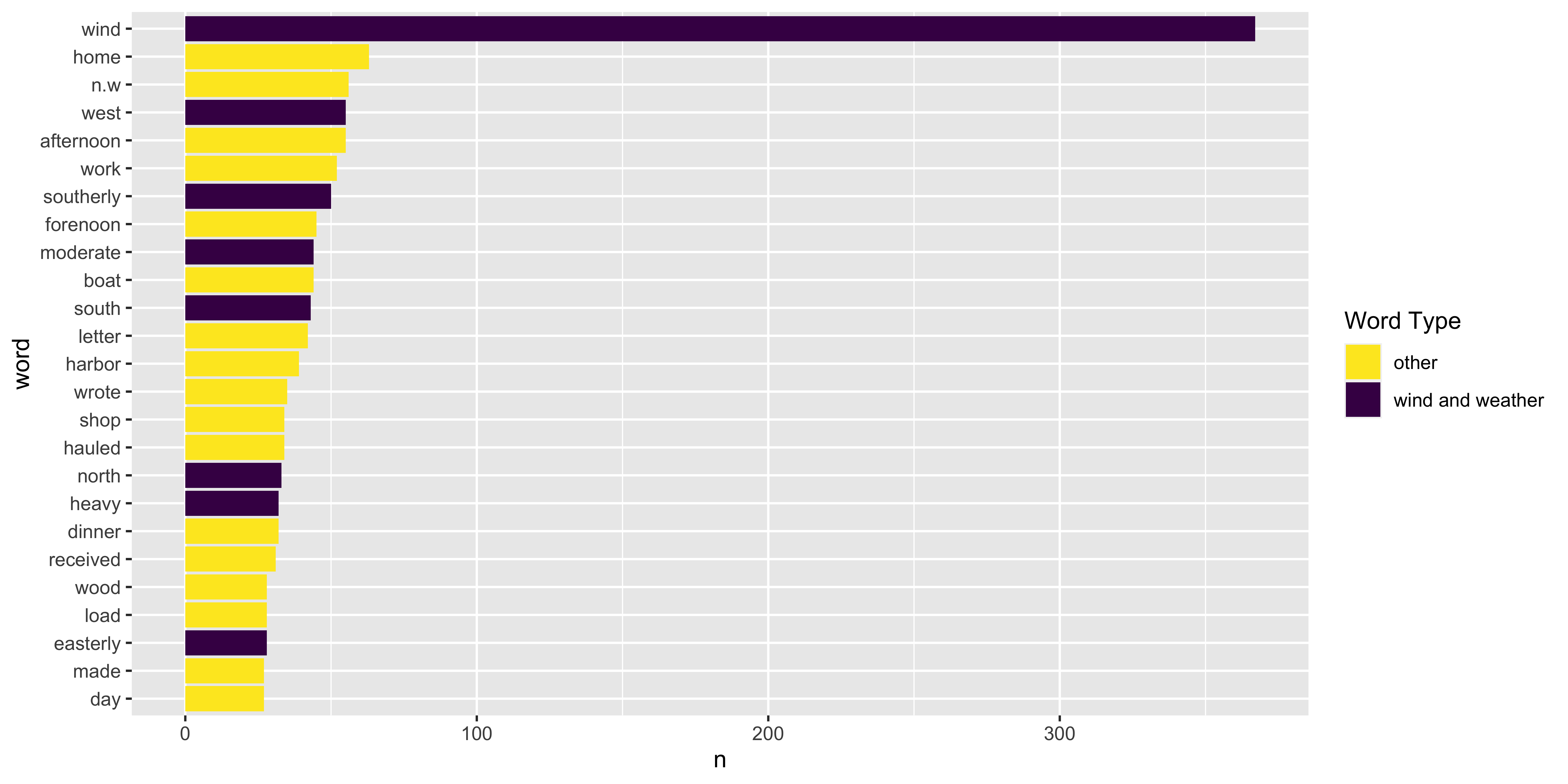
Comparing multiple journals
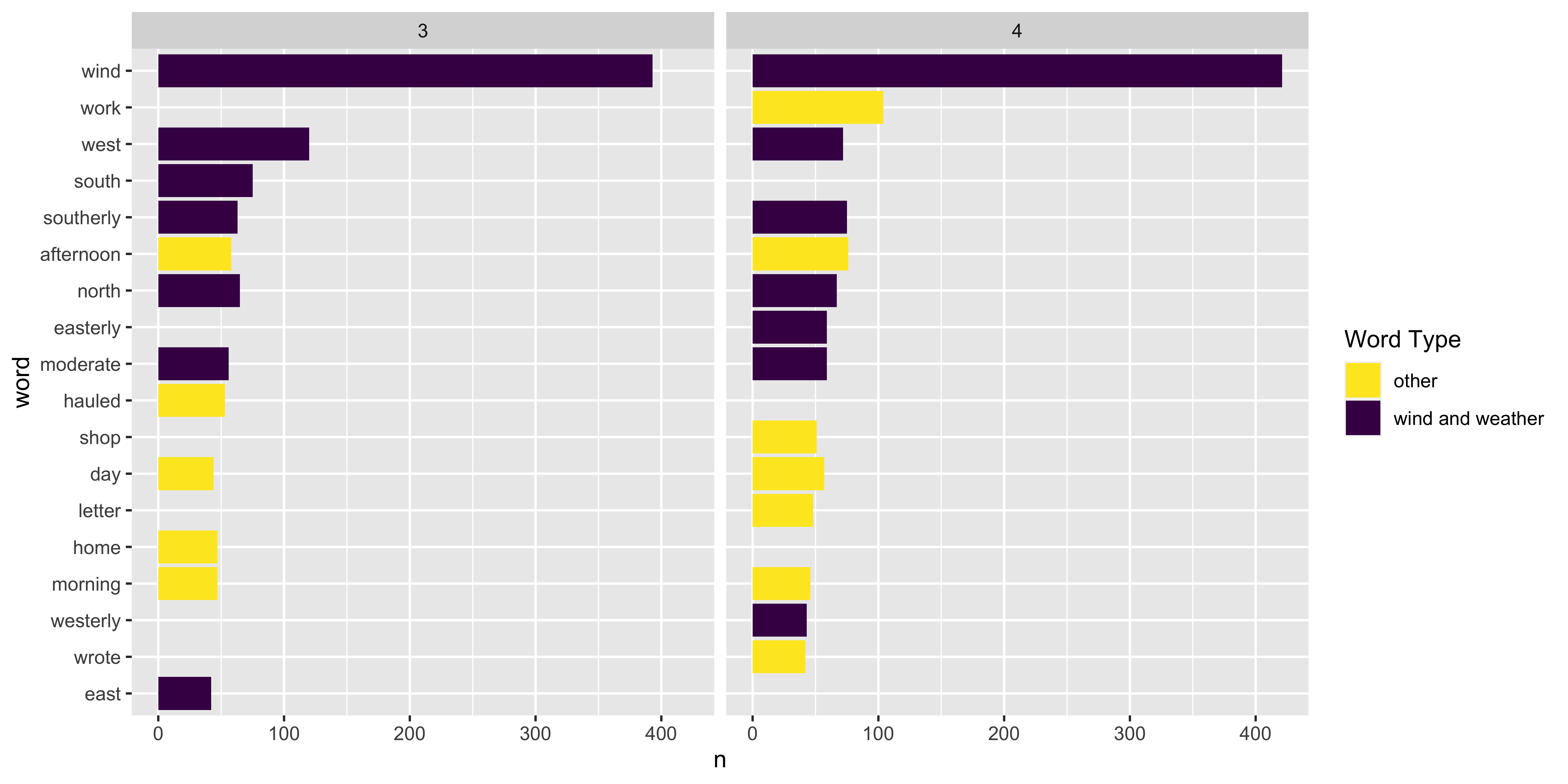
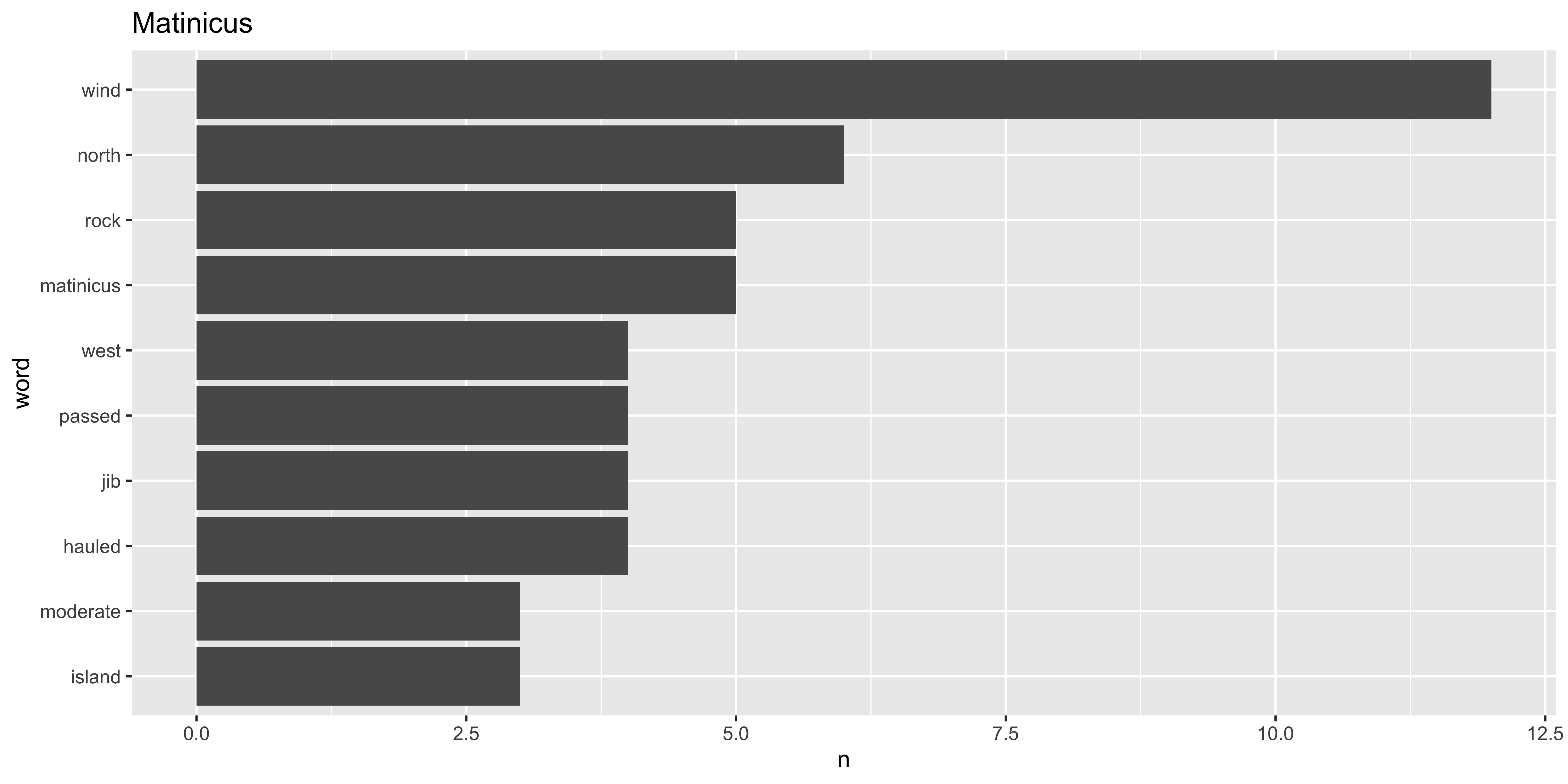
Looking at word trends through space
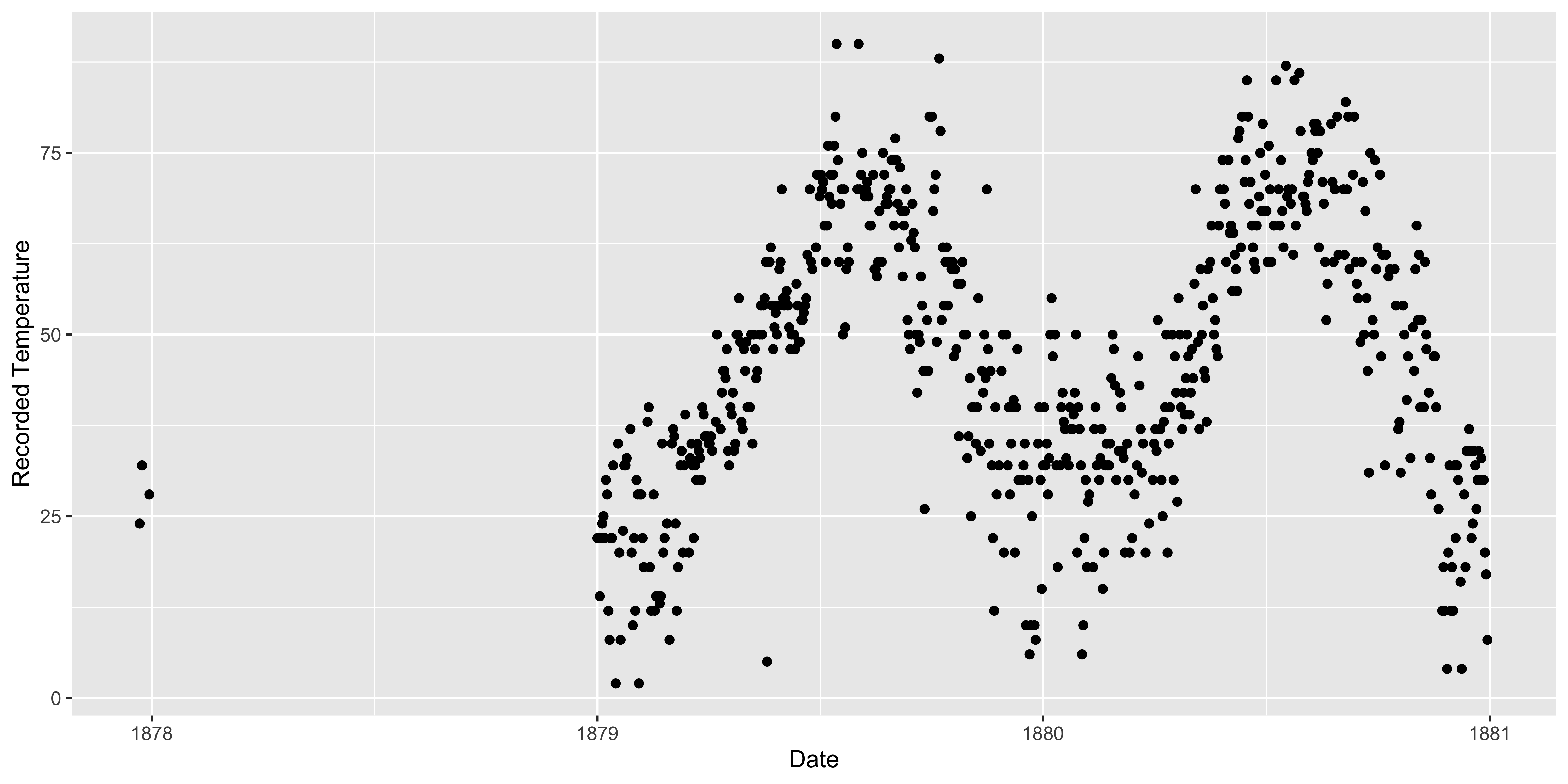
Extracting thermometer readings
Thanks!